汇编语言 —— 更灵活的定位内存地址的方法
1 大小写转换的问题
1.1 and 和 or 指令
- and 指令:逻辑与指令,按位进行与运算;
- or 指令:逻辑或指令,按位进行或运算。
1.2 ASCII 码
一个文本编辑过程中,就包含着按照 ASCII 编码规则进行的编码和解码。在文本编辑过程中,我们按一下键盘的 a 键,就会在屏幕上看到 “a”。
我们按下键盘的 a 键,这个按键的信息被送入计算机,计算机用 ASCII 码的规则对其进行编码,将其转化为 61H 存储在内存的指定空间中;文本编辑软件从内存中取出 61H,将其送到显卡上的显存中;工作在文本模式下的显卡,用 ASCII 码的规则解释显存中的内容, 61H 被当作字符 “a”,显卡驱动显示器,将字符 “a” 的图像画在屏幕上。
1.3 以字符形式给出的数据
在汇编程序中,用 ‘……’ 的方式指明数据是以字符的形式给出的,编译器将把它们转化为相对应的 ASCII 码。
assume cs:code, ds:data
data segment
db 'unTY' ; 相当于 "db 75H,6EH,49H,58H"
db 'fORK' ; 相当于 "db 66H,6FH,52H,4BH"
data ends
code segment
start: ...
code ends
end start1.4 大小写转换
要改变一个字母的大小写,实际上就是要改变它所对应的 ASCII 码,一些字母的 ASCII 码如下表所示:
| 大写 / 小写 | 大写十六进制 | 大写二进制 | 小写十六进制 | 小写二进制 |
|---|---|---|---|---|
| A / a | 41 | 01000001 | 61 | 01100001 |
| B / b | 42 | 01000010 | 62 | 01100010 |
| C / c | 43 | 01000011 | 63 | 01100011 |
| D / d | 44 | 01000100 | 64 | 01100100 |
| E / e | 45 | 01000101 | 65 | 01100101 |
| F / f | 46 | 01000110 | 66 | 01100110 |
由上表可以得出大小写字母 ASCII 码的规律:
- 小写字母的 ASCII 码值比大写字母的 ASCII 码值大 20H;
- 大写字母 ASCII 码的第 5 位为 0,小写字母的第 5 位为 1,其余各位都一样。
我们通过规律 2,配合 and 和 or 指令,可以实现字母的大小写转换。
and al, 11011111B ; 将 al 中的 ASCII 码的第 5 位置为 0,变为大写字母
or al, 00100000B ; 将 al 中的 ASCII 码的第 5 位置为 1,变为小写字母2 更灵活的定位内存地址方法
之前,我们使用 [bx] 方式来指明一个内存单元。现在介绍几种更加灵活的定位内存地址的方式。
2.1 [bx + idata]
[bx + idata] 表示一个内存单元,它的偏移地址为(bx) + idata (bx 中的数值加上 idata)。
指令 mov ax,[bx+200],表示:
- 将一个内存单元的内容送入 ax,这个内存单元的长度为 2 个字节(字单元),存放一个字,偏移地址为 bx 中的数值加上 200,段地址在 ds 中。
该指令也可以写成如下格式:
mov ax, [200+bx]
mov ax, 200[bx]
mov ax, [bx].200汇编语言中 [bx + idata] 的表示方式,为高级语言实现数组提供了便利机制:
- C 语言:a[i]
- 汇编语言:200[bx]
2.2 [bx + si] 和 [bx + di]
si 和 di 是 8086CPU 中和 bx 功能相近的寄存器,区别是 si 和 di 不能够分成两个 8 位寄存器来使用。
表示一个内存单元,它的偏移地址为 (6x)+(si) (即 bx 中的数值加上 si 中的数值)。
指令 mov ax,[bx+si] 表示:
- 将一个内存单元的内容送入 ax,这个内存单元的长度为 2 字节(字单元),存放一个字,偏移地址为 bx 中的数值加上 si 中的数值,段地址在 ds 中。
该指令也可以写成如下格式:mov ax, [bx][si]。
[bx + di] 含义与 [bx + si] 相同。
2.3 [bx + si + idata] 和 [bx + di + idata]
[bx + si + idata] 表示一个内存单元,它的偏移地址为 (bx)+(si)+idata (即 bx 中的数值加上 si 中的数值再加上 idata)。
指令 mov ax, [bx+si+idata] 表示:
将一个内存单元的内容送入 ax,这个内存单元的长度为 2 字节(字单元),存放一个字,偏移地址为 bx 中的数值加上 si 中的数值再加上 idata,段地址在 ds 中。
该指令也可以写成如下格式:
mov ax, [bx+200+si]
mov ax, [200+bx+si]
mov ax, 200[bx][si]
mov ax, [bx].200[si]
mov ax, [bx][si].200[bx + di + idata] 含义与 [bx + si + idata] 相同。
3 不同寻址方式的灵活应用
首先对目前学习过的寻址方式做一个小结:
- [idata] 用一个常量来表示地址,可用于直接定位一个内存单元;
- [bx] 用一个变量来表示内存地址,可用于间按定位 一个内存单元;
- [bx+idata] 用一个变量和常量表示地址,可在一个起始地址的基础上用变量间接定位一个内存单元;
- [bx+si] 用两个变量表示地址;
- [bx+si+idata] 用两个变量和一个常量表示地址。
从 [idata] 一直到 [bx+si+idata],我们可以用更加灵活的方式来定位一个内存单元的地址。这使我们可以从更加结构化的角度来看待所要处理的数据。
3.1 寻址方式编程练习
将 datasg 段中每个单词的前 4 个字母改为大写字母。
datasg segment
db '1. display '
db '2. brows '
db '3. replace '
db '4. modify '
datasg ends分析:datasg 中的数据的存储结构如下图所示:
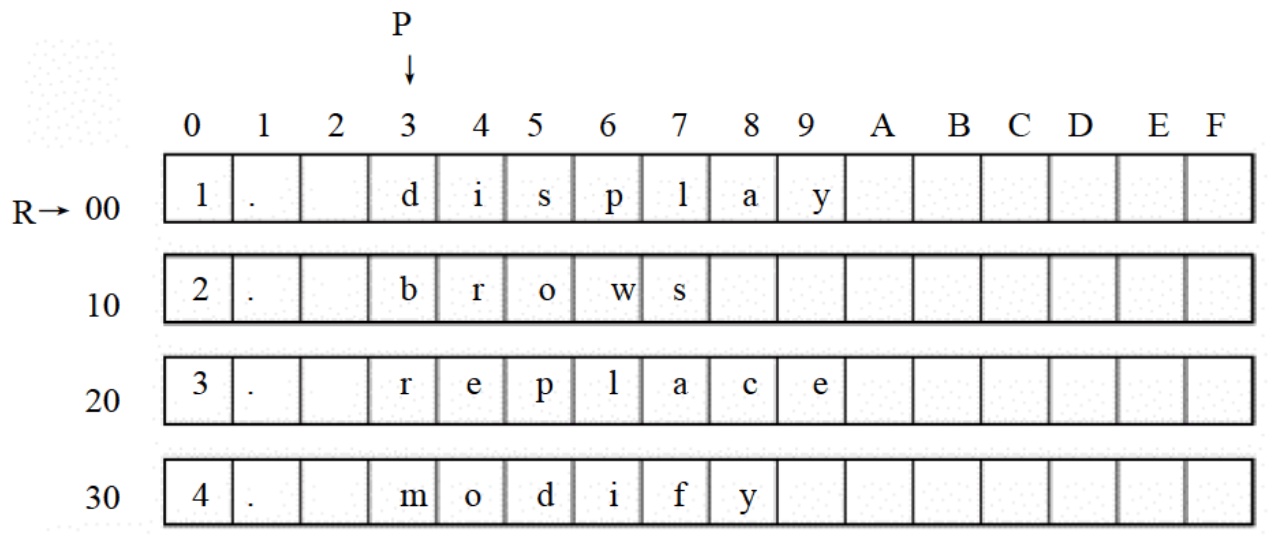
经分析,我们需要进行 4x4 次的二重循环来处理数据:
- 用 bx 来作变量,定位每行的起始地址,用 si 定位要修改的列,用 [bx+3+si] 的方式来对目标单元进行寻址;
- 用栈来暂存外层循环的 cx 值。
代码如下:
assume cs:codesg, ss:stacksg, ds:datasg
stacksg segment
dw 0,0,0,0,0,0,0,0
stacksg ends
datasg segment
db '1. display '
db '2. brows '
db '3. replace '
db '4. modify '
datasg ends
codesg segment
start: mov ax, stacksg
mov ss, ax
mov sp, 16
mov ax, datasg
mov ds, ax
mov bx, 0 ; bx 定位每行的起始地址
mov cx, 4
s0: push cx ; 将外层循环的 cx 值压栈
mov cx, 4
mov si, 0 ; si 定位相对于起始列(3)要修改的列
s: mov al, [bx+si+3]
and al, 11011111B
mov [bx+si+3], al
inc si
loop s
add bx, 16
pop cx ; 恢复外层循环 cx
loop s0
mov ax, 4c00H
int 21H
codesg ends
end start4 重点小结
- and、or 指令;
- 大小写转化的方法;
- 寻址方式 的意义和应用;
- 二重循环问题的处理;
- 栈的应用:一般来说,在需要暂存数据的时候,我们都应该使用栈。