Inside the Apache Kafka Broker
1 Kafka Manages Data and Metadata Separately
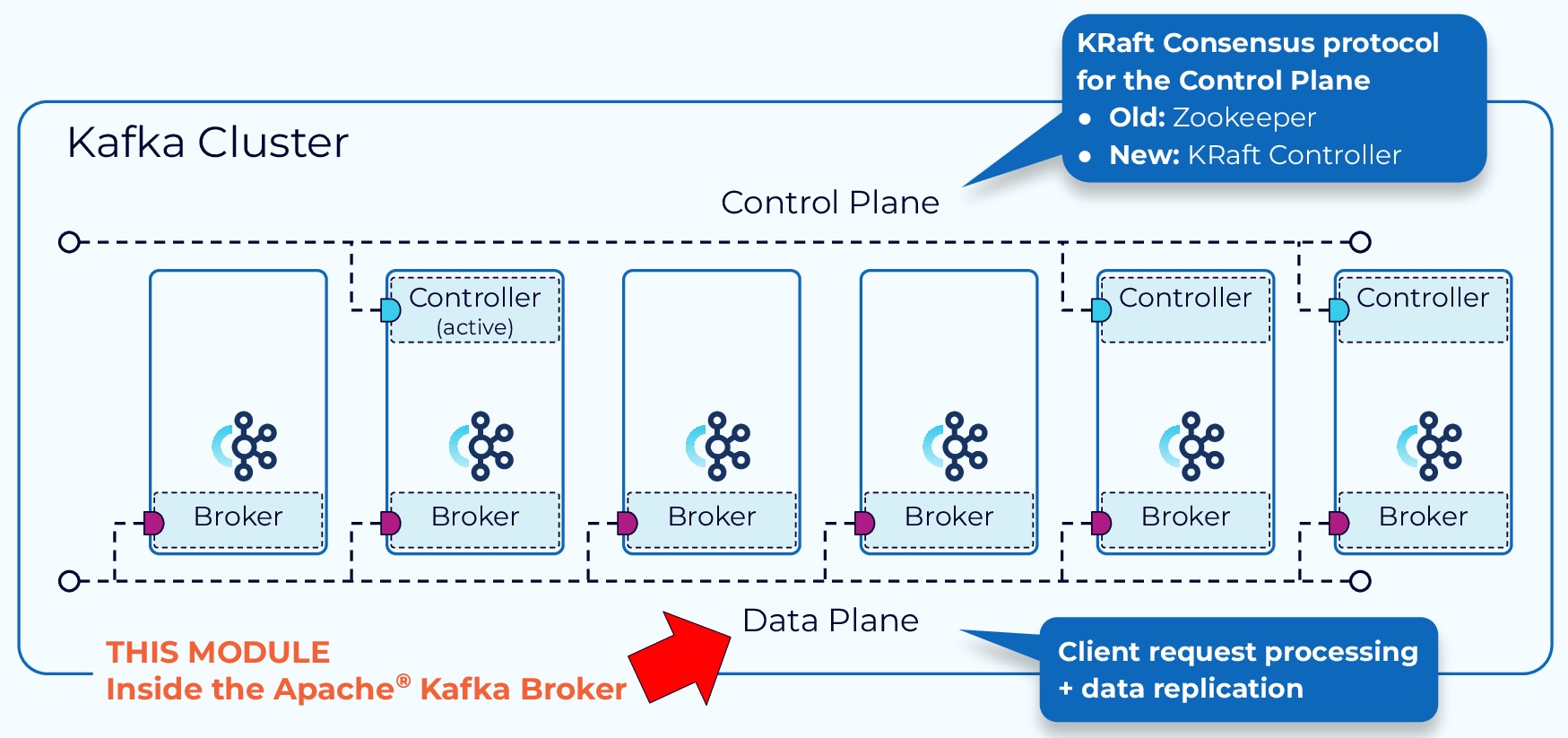
The functions within a Kafka cluster are broken up into a data plane and a control plane.
- The control plane handles management of all the metadata in the cluster.
- The data plane deals with the actual data that we are writing to and reading from Kafka.
1.1 Inside the Apache Kafka Broker
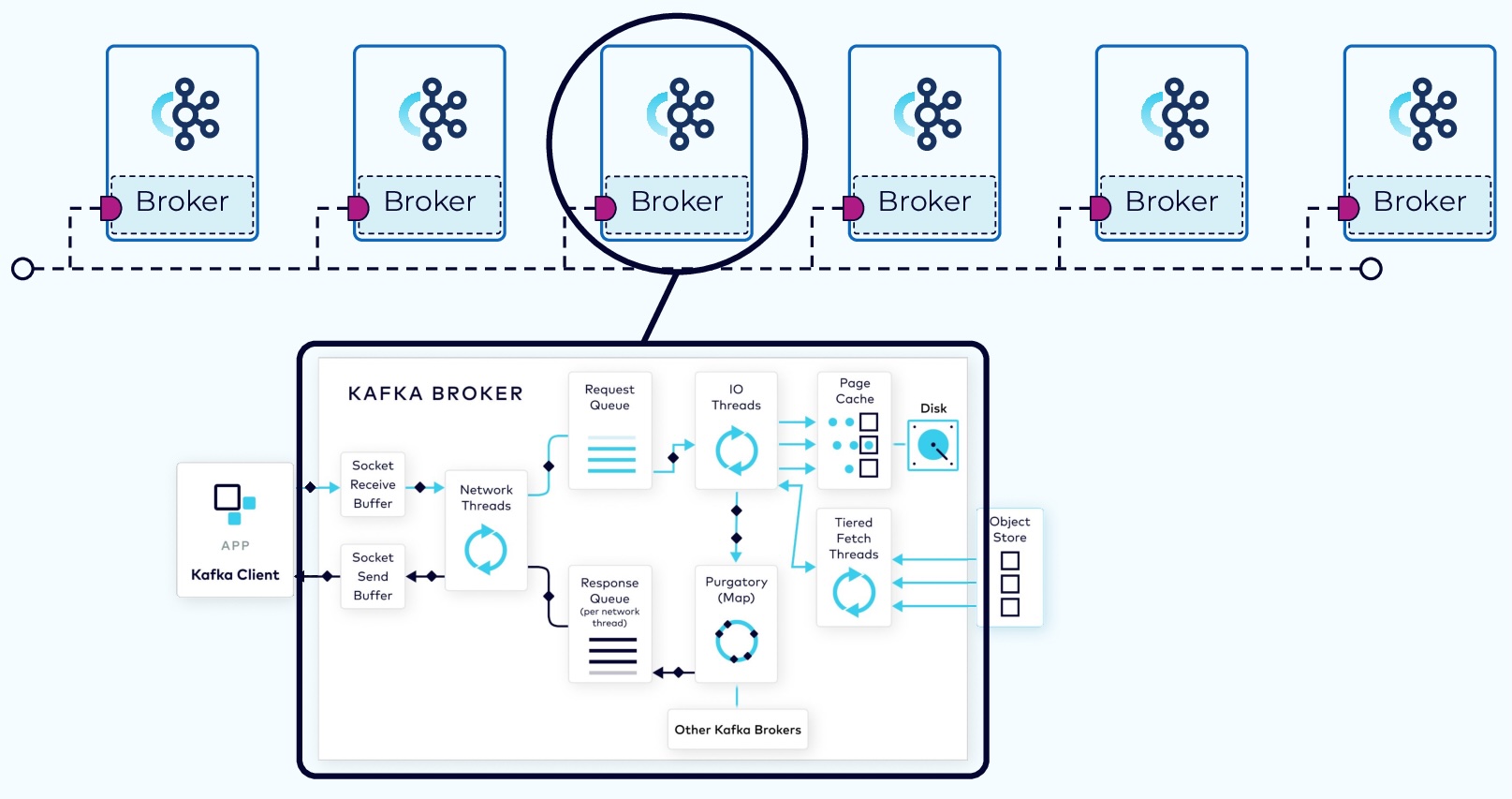
Client requests fall into two categories: produce requests and fetch requests.
- A produce request is requesting that a batch of data be written to a specified topic.
- A fetch request is requesting data from Kafka topics.
1.2 The Produce Request
1.2.1 Network Thread Adds Request to Queue
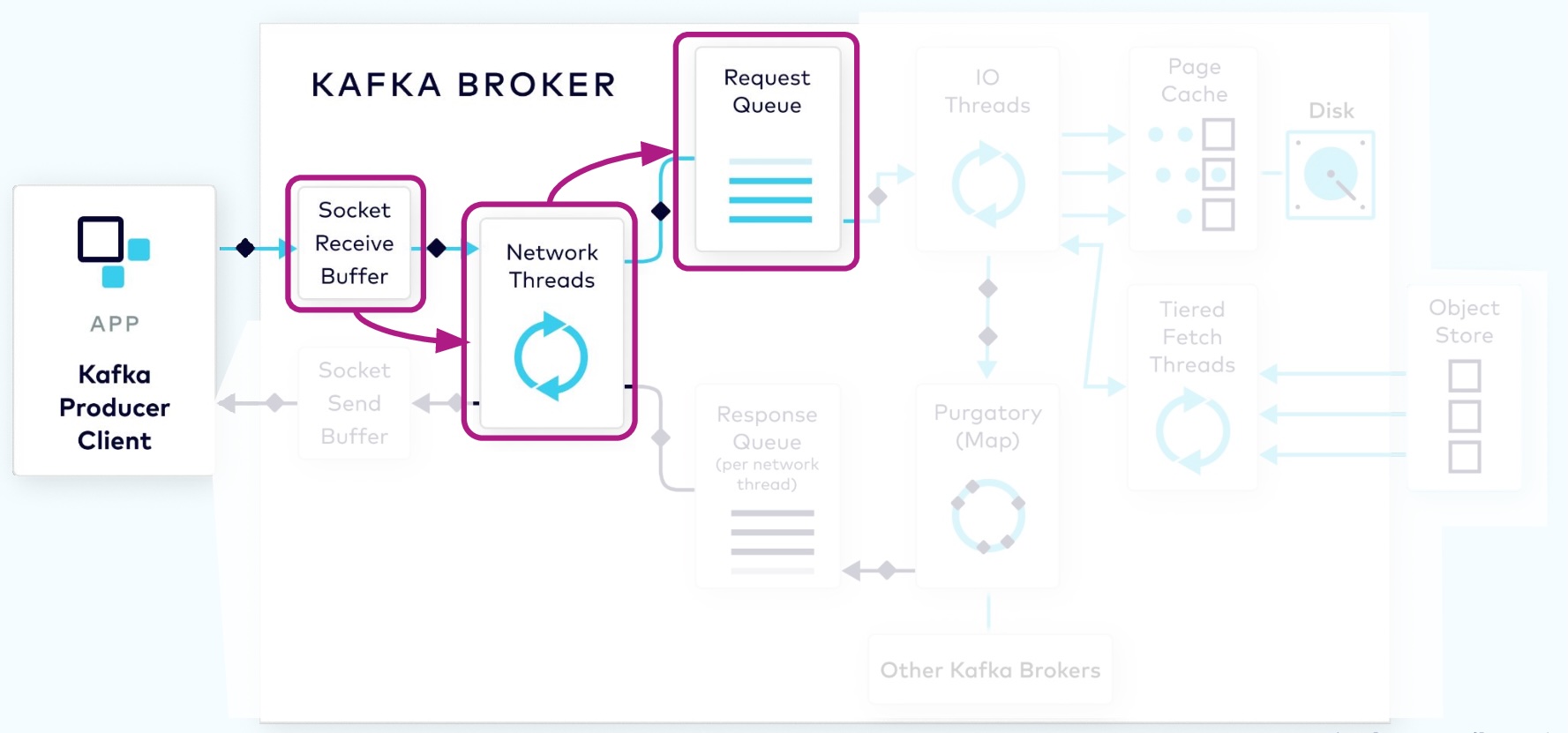
The request first lands in the broker’s socket receive buffer where it will be picked up by a network thread from the pool. That network thread will handle that particular client request through the rest of its lifecycle. The network thread will read the data from the socket buffer, form it into a produce request object, and add it to the request queue.
1.2.2 I/O Thread Verifies and Stores the Batch
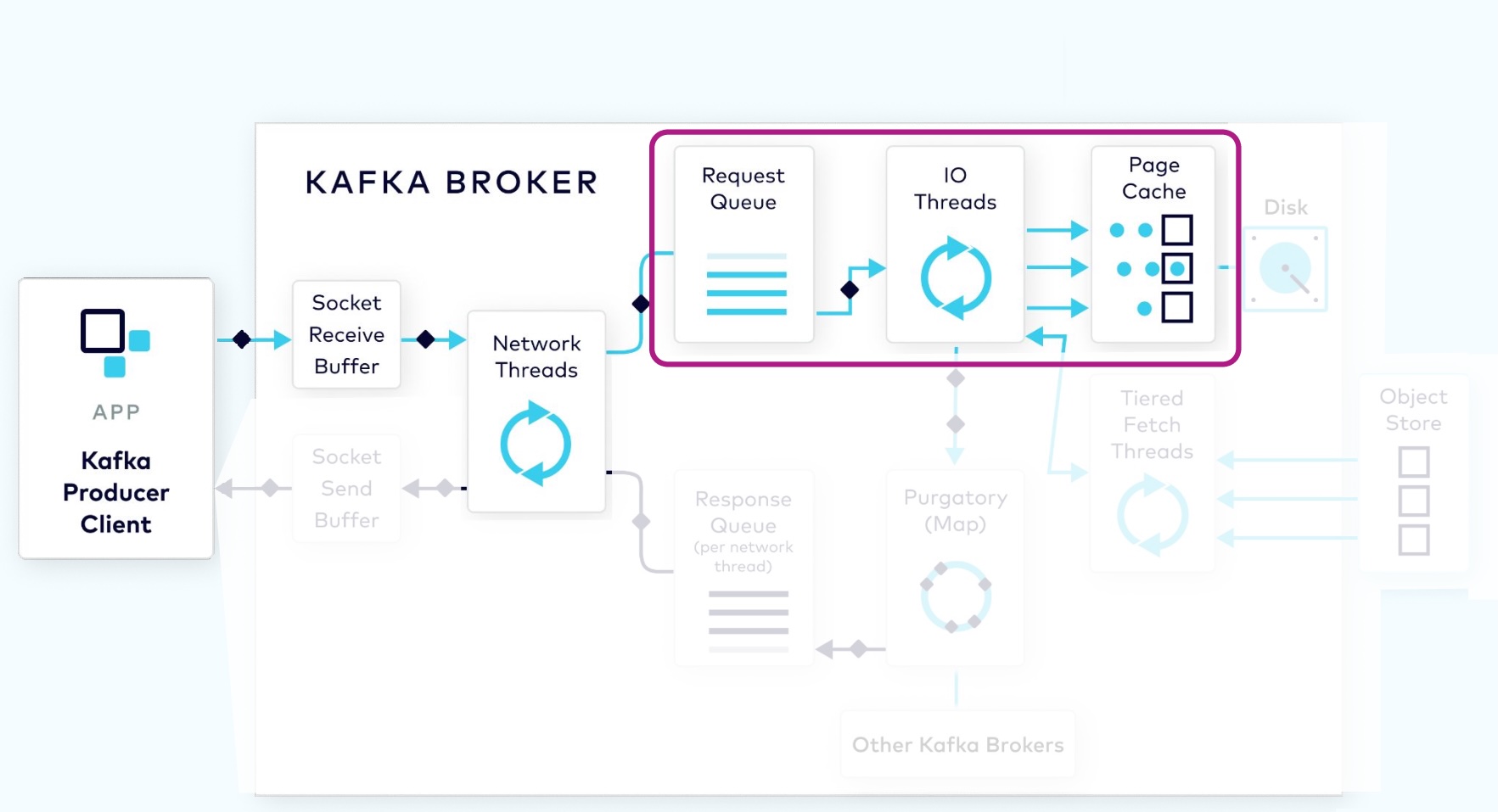
Next, a thread from the I/O thread pool will pick up the request from the queue. The I/O thread will perform some validations, including a CRC check of the data in the request. It will then append the data to the physical data structure of the partition, which is called a commit log.
1.2.3 Kafka Physical Storage
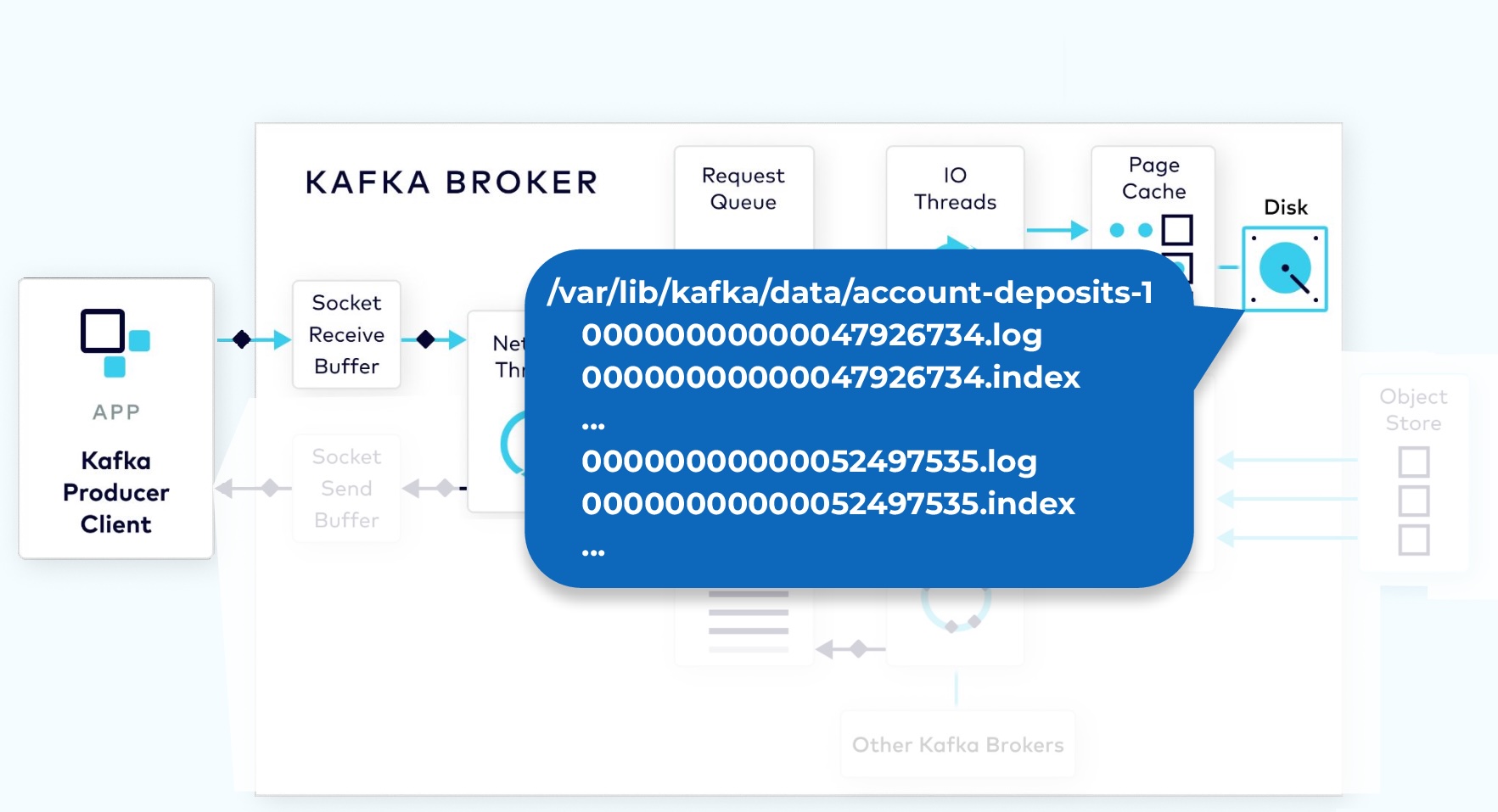
On disk, the commit log is organized as a collection of segments. Each segment is made up of several files. One of these, a .log file, contains the event data. A second, a .index file, contains an index structure, which maps from a record offset to the position of that record in the .log file.
1.2.4 Purgatory Holds Requests Until Replicated
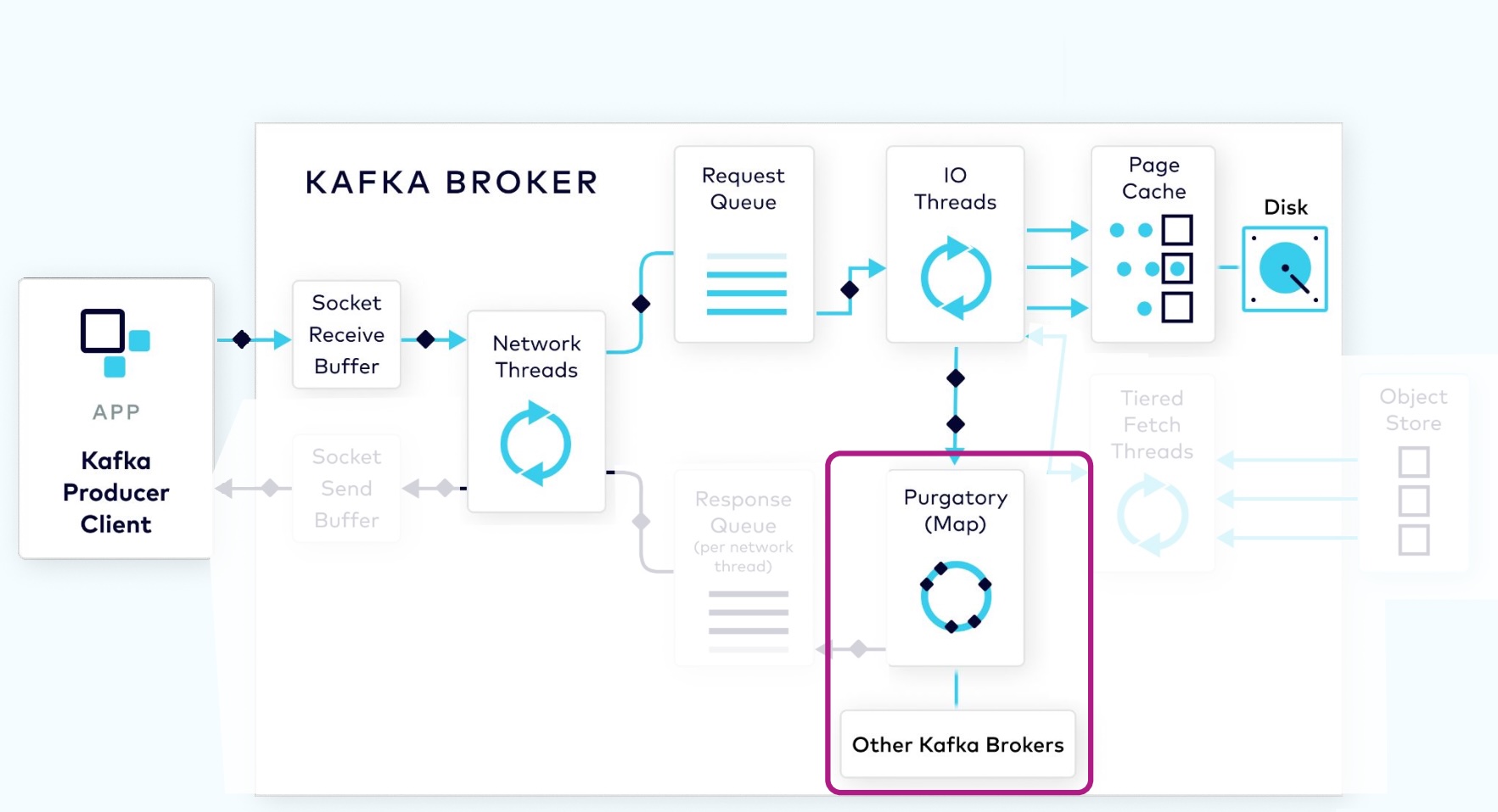
Since the log data is not flushed from the page cache to disk synchronously, Kafka relies on replication to multiple broker nodes, in order to provide durability. By default, the broker will not acknowledge the produce request until it has been replicated to other brokers.
To avoid tying up the I/O threads while waiting for the replication step to complete, the request object will be stored in a map-like data structure called purgatory (it’s where things go to wait).
Once the request has been fully replicated, the broker will take the request object out of purgatory, generate a response object, and place it on the response queue.
1.2.5 Response Added to Socket
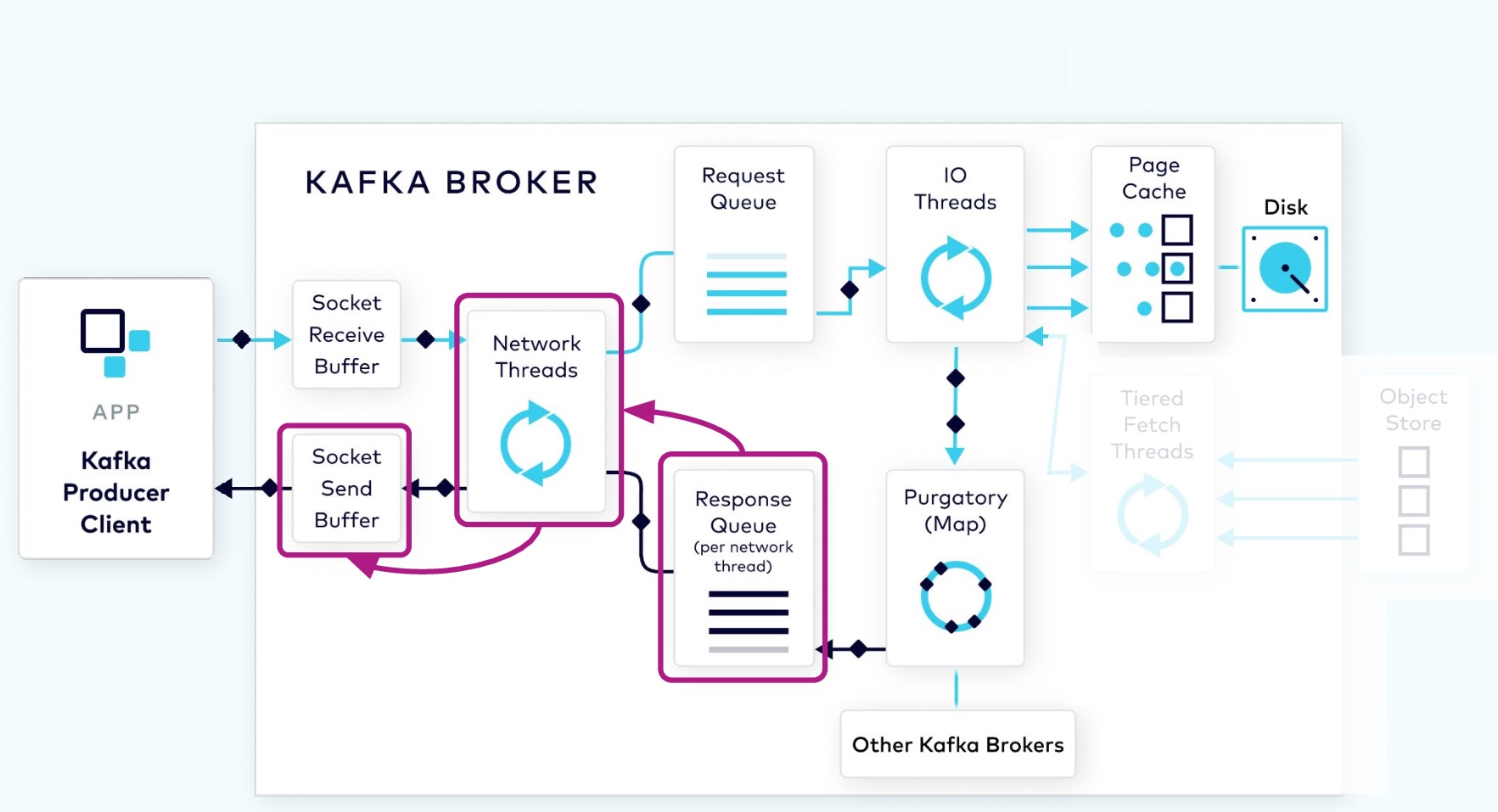
From the response queue, the network thread will pick up the generated response, and send its data to the socket send buffer. The network thread also enforces ordering of requests from an individual client by waiting for all of the bytes for a response from that client to be sent before taking another object from the response queue.
1.3 The Fetch Request
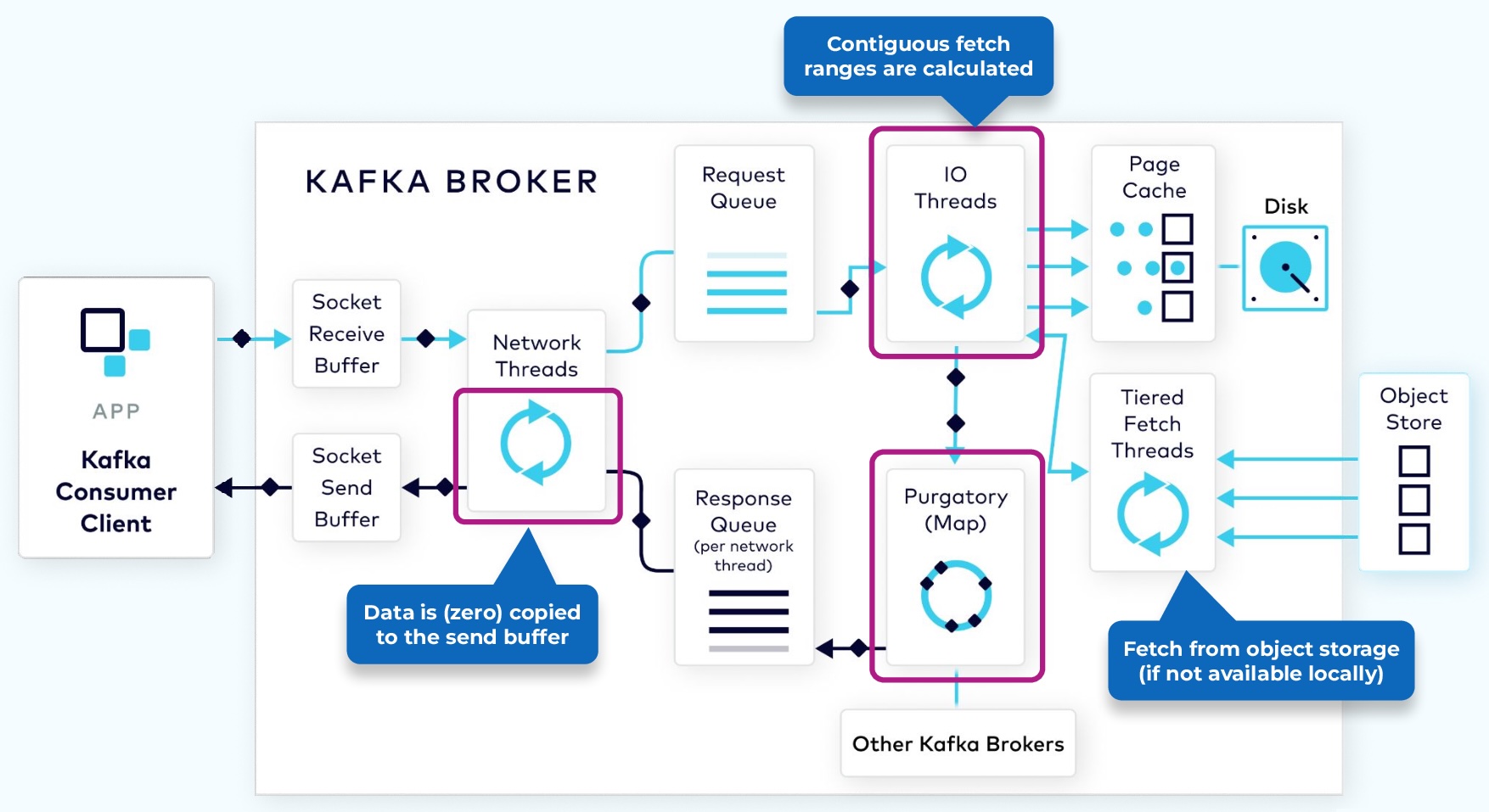
In order to consume records, a consumer client sends a fetch request to the broker, specifying the topic, partition, and offset it wants to consume. The fetch request goes to the broker’s socket receive buffer where it is picked up by a network thread. The network thread puts the request in the request queue, as was done with the produce request.
The I/O thread will take the offset that is included in the fetch request and compare it with the .index file that is part of the partition segment. That will tell it exactly the range of bytes that need to be read from the corresponding .log file to add to the response object.
However, it would be inefficient to send a response with every record fetched, or even worse, when there are no records available. To be more efficient, consumers can be configured to wait for a minimum number of bytes of data, or to wait for a maximum amount of time before returning a response to a fetch request. While waiting for these criteria to be met, the fetch request is sent to purgatory.
Once the size or time requirements have been met, the broker will take the fetch request out of purgatory and generate a response to be sent back to the client. The rest of the process is the same as the produce request.
2 源码分析
2.1 Data Plane And Control Plane
Kafka supports two types of request planes :
-
data-plane :
- Handles requests from clients and other brokers in the cluster.
- The threading model is 1 Acceptor thread per listener, that handles new connections. It is possible to configure multiple data-planes by specifying multiple “,” separated endpoints for “listeners” in KafkaConfig. Acceptor has N Processor threads that each have their own selector and read requests from sockets M Handler threads that handle requests and produce responses back to the processor threads for writing.
-
control-plane :
- Handles requests from controller. This is optional and can be configured by specifying “control.plane.listener.name”. If not configured, the controller requests are handled by the data-plane.
- The threading model is 1 Acceptor thread that handles new connections Acceptor has 1 Processor thread that has its own selector and read requests from the socket. 1 Handler thread that handles requests and produces responses back to the processor thread for writing.
2.2 Produce Request 流程
2.2.1 Network Thread
class SocketServer(val config: KafkaConfig,
val metrics: Metrics,
val time: Time,
val credentialProvider: CredentialProvider,
val apiVersionManager: ApiVersionManager)
extends Logging with BrokerReconfigurable {
// data-plane
private[network] val dataPlaneAcceptors = new ConcurrentHashMap[EndPoint, DataPlaneAcceptor]()
val dataPlaneRequestChannel = new RequestChannel(maxQueuedRequests, DataPlaneAcceptor.MetricPrefix, time, apiVersionManager.newRequestMetrics)
// control-plane
private[network] var controlPlaneAcceptorOpt: Option[ControlPlaneAcceptor] = None
val controlPlaneRequestChannelOpt: Option[RequestChannel] = config.controlPlaneListenerName.map(_ =>
new RequestChannel(20, ControlPlaneAcceptor.MetricPrefix, time, apiVersionManager.newRequestMetrics))
}对于 Data Plane,dataPlaneAcceptors 在每个端口指定一个 DataPlaneAcceptor 线程处理新连接,将请求写到 socket receive buffer 中。
RequestChannel 封装了 Network Threads 和 RequestQueue。代码如下:
class RequestChannel(val queueSize: Int,
val metricNamePrefix: String,
time: Time,
val metrics: RequestChannel.Metrics) {
private val requestQueue = new ArrayBlockingQueue[BaseRequest](queueSize)
private val processors = new ConcurrentHashMap[Int, Processor]()
/** Send a request to be handled, potentially blocking until there is room in the queue for the request */
def sendRequest(request: RequestChannel.Request): Unit = {
requestQueue.put(request)
}
}processors 就是 Kafka 中的 Network Threads,负责将请求数据从 socket buffer 中读取出来,生成 Request 对象并加入到 RequestQueue 中。
private[kafka] class Processor(
// ...
) extends Runnable with Logging {
private def processCompletedReceives(): Unit = {
selector.completedReceives.forEach { receive =>
// ...
val connectionId = receive.source
val context = new RequestContext(header, connectionId, channel.socketAddress,
channel.principal, listenerName, securityProtocol,
channel.channelMetadataRegistry.clientInformation, isPrivilegedListener, channel.principalSerde)
val req = new RequestChannel.Request(processor = id, context = context,
startTimeNanos = nowNanos, memoryPool, receive.payload, requestChannel.metrics, None)
// ...
requestChannel.sendRequest(req)
}
}2.2.2 I/O Thread
类 KafkaRequestHandlerPool 就是 I/O Thread Pool。每个 KafkaRequestHandler 就是 I/O Thread。
I/O Thread 从 RequestQueue 中获取请求,调用 KafkaApis.handle() 方法执行该请求对应的方法。
class KafkaRequestHandlerPool(val brokerId: Int,
val requestChannel: RequestChannel,
val apis: ApiRequestHandler,
time: Time,
numThreads: Int,
requestHandlerAvgIdleMetricName: String,
logAndThreadNamePrefix : String) extends Logging {
// 线程池
val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads)
}
/**
* A thread that answers kafka requests.
*/
class KafkaRequestHandler(id: Int,
brokerId: Int,
val aggregateIdleMeter: Meter,
val totalHandlerThreads: AtomicInteger,
val requestChannel: RequestChannel,
apis: ApiRequestHandler,
time: Time) extends Runnable with Logging {
// ...
// 从 RequestQueue 中获取请求
val req = requestChannel.receiveRequest(300)
req match {
case request: RequestChannel.Request =>
// 调用 KafkaApis.handle 方法
apis.handle(request, requestLocal)
// ...
}
}KafkaApis.handle() 处理所有请求并分发到相应的方法。
/**
* Top-level method that handles all requests and multiplexes to the right api
*/
override def handle(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {
request.header.apiKey match {
case ApiKeys.PRODUCE => handleProduceRequest(request, requestLocal)
case ApiKeys.FETCH => handleFetchRequest(request)
// ...
}
}接下来分析一下 handleProduceRequest() 方法,解析 I/O 线程如何将数据写入 Commit Log 中。
/**
* Handle a produce request
*/
def handleProduceRequest(request: RequestChannel.Request, requestLocal: RequestLocal): Unit = {
// 获取 ProduceRequest 内容
val produceRequest = request.body[ProduceRequest]
// 将校验通过的数据存入 authorizedRequestInfo 中
val authorizedRequestInfo = mutable.Map[TopicPartition, MemoryRecords]()
produceRequest.data.topicData.forEach(topic => topic.partitionData.forEach { partition =>
val topicPartition = new TopicPartition(topic.name, partition.index)
val memoryRecords = partition.records.asInstanceOf[MemoryRecords]
authorizedRequestInfo += (topicPartition -> memoryRecords)
})
// 调用 replicaManager 将 authorizedRequestInfo 数据写入 Commit Log
// call the replica manager to append messages to the replicas
replicaManager.appendRecords(
entriesPerPartition = authorizedRequestInfo)
}/**
* Append messages to leader replicas of the partition, and wait for them to be replicated to other replicas
*/
def appendRecords(
entriesPerPartition: Map[TopicPartition, MemoryRecords]
): Unit = {
// 代码有所简化
var verifiedEntriesPerPartition = entriesPerPartition
// 调用 appendEntries 方法
appendEntries(verifiedEntriesPerPartition, internalTopicsAllowed, origin, requiredAcks, verificationGuards.toMap,
errorsPerPartition, recordConversionStatsCallback, timeout, responseCallback, delayedProduceLock)(requestLocal, Map.empty)
}
private def appendEntries(
allEntries: Map[TopicPartition, MemoryRecords]
): Unit = {
val verifiedEntries =
if (unverifiedEntries.isEmpty)
allEntries
else
allEntries.filter { case (tp, _) =>
!unverifiedEntries.contains(tp)
}
// 将通过校验的数据写入
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, verifiedEntries, requiredAcks, requestLocal, verificationGuards.toMap)
}
/**
* Append the messages to the local replica logs
*/
private def appendToLocalLog(
entriesPerPartition: Map[TopicPartition, MemoryRecords]
): Map[TopicPartition, LogAppendResult] = {
entriesPerPartition.map { case (topicPartition, records) =>
// 获得写入的 partition
val partition = getPartitionOrException(topicPartition)
// 写入到 partition 的 leader 中
val info = partition.appendRecordsToLeader(records, origin, requiredAcks, requestLocal, verificationGuards.getOrElse(topicPartition, null))
}
}def appendRecordsToLeader(
records: MemoryRecords
): LogAppendInfo = {
leaderLogIfLocal match {
// 如果 partition 的 leader 在此 broker 上,写入数据
case Some(leaderLog) =>
val info = leaderLog.appendAsLeader(records, leaderEpoch = this.leaderEpoch, origin,
interBrokerProtocolVersion, requestLocal, verificationGuard)
// 否则抛出 NotLeaderOrFollowerException
case None =>
throw new NotLeaderOrFollowerException("Leader not local for partition %s on broker %d"
.format(topicPartition, localBrokerId))
}
}/**
* Append this message set to the active segment of the local log, assigning offsets and Partition Leader Epochs
*/
def appendAsLeader(
records: MemoryRecords
): LogAppendInfo = {
append(records, origin, interBrokerProtocolVersion, validateAndAssignOffsets, leaderEpoch, Some(requestLocal), verificationGuard, ignoreRecordSize = false)
}
/**
* Append this message set to the active segment of the local log, rolling over to a fresh segment if necessary.
*
* This method will generally be responsible for assigning offsets to the messages,
* however if the assignOffsets=false flag is passed we will only check that the existing offsets are valid.
*/
private def append(
records: MemoryRecords,
): LogAppendInfo = {
// 校验消息的 CRC 或其他的校验
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize, leaderEpoch)
// assign offsets to the message set
val offset = PrimitiveRef.ofLong(localLog.logEndOffset)
// 将 validRecords 写入本地
localLog.append(appendInfo.lastOffset, appendInfo.maxTimestamp, appendInfo.offsetOfMaxTimestamp, validRecords)
// 更新本地的 HighWatermark
updateHighWatermarkWithLogEndOffset()
// 判断是否需要将数据 flush 进磁盘
if (localLog.unflushedMessages >= config.flushInterval) flush(false)
}private[log] def append(
records: MemoryRecords
): Unit = {
// 将 records 写入当前的 activeSegment
segments.activeSegment.append(largestOffset = lastOffset, largestTimestamp = largestTimestamp,
shallowOffsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp, records = records)
updateLogEndOffset(lastOffset + 1)
}/**
* Append the given messages starting with the given offset. Add
* an entry to the index if needed.
*
* It is assumed this method is being called from within a lock.
*/
def append(
records: MemoryRecords
): Unit = {
// append the messages
val appendedBytes = log.append(records)
}/**
* Append a set of records to the file. This method is not thread-safe and must be
* protected with a lock.
*
* @param records The records to append
* @return the number of bytes written to the underlying file
*/
public int append(MemoryRecords records) throws IOException {
// 将 records 写入到 channel
int written = records.writeFullyTo(channel);
size.getAndAdd(written);
return written;
}当 I/O Thread 将数据写入到本地后,会将这些请求添加到 Purgatory 中,等待 Replica 写入这些数据。
private def appendEntries(
allEntries: Map[TopicPartition, MemoryRecords]
): Unit = {
val localProduceResults = appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed,
origin, verifiedEntries, requiredAcks, requestLocal, verificationGuards.toMap)
val allResults = localProduceResults ++ unverifiedResults ++ errorResults
if (delayedProduceRequestRequired(requiredAcks, allEntries, allResults)) {
// create delayed produce operation
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
// create a list of (topic, partition) pairs to use as keys for this delayed produce operation
val producerRequestKeys = allEntries.keys.map(TopicPartitionOperationKey(_)).toSeq
// try to complete the request immediately, otherwise put it into the purgatory
// this is because while the delayed produce operation is being created, new
// requests may arrive and hence make this operation completable.
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)
} else {
// we can respond immediately
val produceResponseStatus = produceStatus.map { case (k, status) => k -> status.responseStatus }
responseCallback(produceResponseStatus)
}
}2.2.3 Purgatory
Purgatory 线程在执行完任务后,会调用 responseCallback() 将响应放入 ResponseQueue 中。
/**
* Check if the operation can be completed, if not watch it based on the given watch keys
*/
def tryCompleteElseWatch(operation: T, watchKeys: Seq[Any]): Boolean = {
if (operation.safeTryCompleteOrElse {
watchKeys.foreach(key => watchForOperation(key, operation))
if (watchKeys.nonEmpty) estimatedTotalOperations.incrementAndGet()
}) return true
// if it cannot be completed by now and hence is watched, add to the expire queue also
if (!operation.isCompleted) {
if (timerEnabled)
timeoutTimer.add(operation)
if (operation.isCompleted) {
// cancel the timer task
operation.cancel()
}
}
false
}
private[server] def safeTryCompleteOrElse(f: => Unit): Boolean = inLock(lock) {
if (tryComplete()) true
else {
f
// last completion check
tryComplete()
}
}/**
* The delayed produce operation can be completed if every partition
* it produces to is satisfied by one of the following:
*
* Case A: Replica not assigned to partition
* Case B: Replica is no longer the leader of this partition
* Case C: This broker is the leader:
* C.1 - If there was a local error thrown while checking if at least requiredAcks
* replicas have caught up to this operation: set an error in response
* C.2 - Otherwise, set the response with no error.
*/
override def tryComplete(): Boolean = {
// check for each partition if it still has pending acks
produceMetadata.produceStatus.forKeyValue { (topicPartition, status) =>
// skip those partitions that have already been satisfied
if (status.acksPending) {
val (hasEnough, error) = replicaManager.getPartitionOrError(topicPartition) match {
case Left(err) =>
// Case A
(false, err)
case Right(partition) =>
partition.checkEnoughReplicasReachOffset(status.requiredOffset)
}
// Case B || C.1 || C.2
if (error != Errors.NONE || hasEnough) {
status.acksPending = false
status.responseStatus.error = error
}
}
}
// check if every partition has satisfied at least one of case A, B or C
if (!produceMetadata.produceStatus.values.exists(_.acksPending))
forceComplete()
else
false
}
/**
* Upon completion, return the current response status along with the error code per partition
*/
override def onComplete(): Unit = {
val responseStatus = produceMetadata.produceStatus.map { case (k, status) => k -> status.responseStatus }
responseCallback(responseStatus)
}def sendResponseCallback(responseStatus: Map[TopicPartition, PartitionResponse]): Unit = {
// Send the response immediately. In case of throttling, the channel has already been muted.
if (produceRequest.acks == 0) {
if (errorInResponse) {
requestChannel.closeConnection(request, new ProduceResponse(mergedResponseStatus.asJava).errorCounts)
} else {
requestHelper.sendNoOpResponseExemptThrottle(request)
}
} else {
requestChannel.sendResponse(request, new ProduceResponse(mergedResponseStatus.asJava, maxThrottleTimeMs), None)
}
}def sendResponse(
request: RequestChannel.Request,
response: AbstractResponse,
onComplete: Option[Send => Unit]
): Unit = {
updateErrorMetrics(request.header.apiKey, response.errorCounts.asScala)
sendResponse(new RequestChannel.SendResponse(
request,
request.buildResponseSend(response),
request.responseNode(response),
onComplete
))
}
/** Send a response back to the socket server to be sent over the network */
private[network] def sendResponse(response: RequestChannel.Response): Unit = {
val processor = processors.get(response.processor)
// The processor may be null if it was shutdown. In this case, the connections
// are closed, so the response is dropped.
if (processor != null) {
processor.enqueueResponse(response)
}
}private[network] def enqueueResponse(response: RequestChannel.Response): Unit = {
responseQueue.put(response)
wakeup()
}2.2.4 Network Thread Add Response to Socket
Network Thread 从 ResponseQueue 中获取响应,写入到 Socket Send Buffer 中。
private def processNewResponses(): Unit = {
var currentResponse: RequestChannel.Response = null
while ({currentResponse = dequeueResponse(); currentResponse != null}) {
currentResponse match {
case response: SendResponse =>
sendResponse(response, response.responseSend)
}
}
}
protected[network] def sendResponse(response: RequestChannel.Response, responseSend: Send): Unit = {
val connectionId = response.request.context.connectionId
if (openOrClosingChannel(connectionId).isDefined) {
selector.send(new NetworkSend(connectionId, responseSend))
inflightResponses += (connectionId -> response)
}
}2.3 Fetch Request 流程
在 Fetch 流程中,Network Thread 的工作与 Produce 流程一样。
I/O Thread 会获取请求中的 Offset 并将其与 Segment 中的 .index 文件比较。从而得知 .log 文件中的字节范围。
/**
* Handle a fetch request
*/
def handleFetchRequest(request: RequestChannel.Request): Unit = {
// 要 Fetch 的请求
val interesting = mutable.ArrayBuffer[(TopicIdPartition, FetchRequest.PartitionData)]()
// call the replica manager to fetch messages from the local replica
replicaManager.fetchMessages(
params = params,
fetchInfos = interesting,
quota = replicationQuota(fetchRequest),
responseCallback = processResponseCallback,
)
}/**
* Fetch messages from a replica, and wait until enough data can be fetched and return;
* the callback function will be triggered either when timeout or required fetch info is satisfied.
* Consumers may fetch from any replica, but followers can only fetch from the leader.
*/
def fetchMessages(params: FetchParams,
fetchInfos: Seq[(TopicIdPartition, PartitionData)]
): Unit = {
// 本地日志读取结果
val logReadResults = readFromLog(params, fetchInfos, quota, readFromPurgatory = false)
// 所有 Partition 的读取结果
val logReadResultMap = new mutable.HashMap[TopicIdPartition, LogReadResult]
logReadResults.foreach { case (topicIdPartition, logReadResult) =>
logReadResultMap.put(topicIdPartition, logReadResult)
}
// 直接返回
// Respond immediately if no remote fetches are required and any of the below conditions is true
// 1. fetch request does not want to wait
// 2. fetch request does not require any data
// 3. has enough data to respond
// 4. some error happens while reading data
// 5. we found a diverging epoch
// 6. has a preferred read replica
if (!remoteFetchInfo.isPresent && (params.maxWaitMs <= 0 || fetchInfos.isEmpty || bytesReadable >= params.minBytes || errorReadingData ||
hasDivergingEpoch || hasPreferredReadReplica)) {
val fetchPartitionData = logReadResults.map { case (tp, result) =>
val isReassignmentFetch = params.isFromFollower && isAddingReplica(tp.topicPartition, params.replicaId)
tp -> result.toFetchPartitionData(isReassignmentFetch)
}
responseCallback(fetchPartitionData)
} else { // 延迟返回
// construct the fetch results from the read results
val fetchPartitionStatus = new mutable.ArrayBuffer[(TopicIdPartition, FetchPartitionStatus)]
fetchInfos.foreach { case (topicIdPartition, partitionData) =>
logReadResultMap.get(topicIdPartition).foreach(logReadResult => {
val logOffsetMetadata = logReadResult.info.fetchOffsetMetadata
fetchPartitionStatus += (topicIdPartition -> FetchPartitionStatus(logOffsetMetadata, partitionData))
})
}
// If there is not enough data to respond and there is no remote data, we will let the fetch request
// wait for new data.
val delayedFetch = new DelayedFetch(
params = params,
fetchPartitionStatus = fetchPartitionStatus,
replicaManager = this,
quota = quota,
responseCallback = responseCallback
)
// create a list of (topic, partition) pairs to use as keys for this delayed fetch operation
val delayedFetchKeys = fetchPartitionStatus.map { case (tp, _) => TopicPartitionOperationKey(tp) }
// try to complete the request immediately, otherwise put it into the purgatory;
// this is because while the delayed fetch operation is being created, new requests
// may arrive and hence make this operation completable.
delayedFetchPurgatory.tryCompleteElseWatch(delayedFetch, delayedFetchKeys)
}
}
/**
* Read from multiple topic partitions at the given offset up to maxSize bytes
*/
def readFromLog(
params: FetchParams
): Seq[(TopicIdPartition, LogReadResult)] = {
val result = new mutable.ArrayBuffer[(TopicIdPartition, LogReadResult)]
readPartitionInfo.foreach { case (tp, fetchInfo) =>
val readResult = read(tp, fetchInfo, limitBytes, minOneMessage)
result += (tp -> readResult)
}
result
}
def read(tp: TopicIdPartition, fetchInfo: PartitionData, limitBytes: Int, minOneMessage: Boolean
): LogReadResult = {
var log: UnifiedLog = null
partition = getPartitionOrException(tp.topicPartition)
log = partition.localLogWithEpochOrThrow(fetchInfo.currentLeaderEpoch, params.fetchOnlyLeader())
// 调用 fetchRecords 读取数据
// Try the read first, this tells us whether we need all of adjustedFetchSize for this partition
val readInfo: LogReadInfo = partition.fetchRecords(
fetchParams = params,
fetchPartitionData = fetchInfo,
fetchTimeMs = fetchTimeMs,
maxBytes = adjustedMaxBytes,
minOneMessage = minOneMessage,
updateFetchState = !readFromPurgatory)
val fetchDataInfo = checkFetchDataInfo(partition, readInfo.fetchedData)
LogReadResult(info = fetchDataInfo,
divergingEpoch = readInfo.divergingEpoch.asScala,
highWatermark = readInfo.highWatermark,
leaderLogStartOffset = readInfo.logStartOffset,
leaderLogEndOffset = readInfo.logEndOffset,
followerLogStartOffset = followerLogStartOffset,
fetchTimeMs = fetchTimeMs,
lastStableOffset = Some(readInfo.lastStableOffset),
preferredReadReplica = preferredReadReplica,
exception = None
)
}/**
* Fetch records from the partition.
*/
def fetchRecords(
fetchParams: FetchParams,
fetchPartitionData: FetchRequest.PartitionData,
): LogReadInfo = {
// 调用 readRecords 读取数据
def readFromLocalLog(log: UnifiedLog): LogReadInfo = {
readRecords(
log,
fetchPartitionData.lastFetchedEpoch,
fetchPartitionData.fetchOffset,
fetchPartitionData.currentLeaderEpoch,
maxBytes,
fetchParams.isolation,
minOneMessage
)
}
// 处理 Follower 的 Fetch 请求
if (fetchParams.isFromFollower) {
// Check that the request is from a valid replica before doing the read
val (replica, logReadInfo) = inReadLock(leaderIsrUpdateLock) {
val localLog = localLogWithEpochOrThrow(
fetchPartitionData.currentLeaderEpoch,
fetchParams.fetchOnlyLeader
)
val replica = followerReplicaOrThrow(
fetchParams.replicaId,
fetchPartitionData
)
val logReadInfo = readFromLocalLog(localLog)
(replica, logReadInfo)
}
// 更新 Follower Fetch 状态
if (updateFetchState && !logReadInfo.divergingEpoch.isPresent) {
updateFollowerFetchState(
replica,
followerFetchOffsetMetadata = logReadInfo.fetchedData.fetchOffsetMetadata,
followerStartOffset = fetchPartitionData.logStartOffset,
followerFetchTimeMs = fetchTimeMs,
leaderEndOffset = logReadInfo.logEndOffset,
fetchParams.replicaEpoch
)
}
logReadInfo
} else { // 处理非 Follower 请求
inReadLock(leaderIsrUpdateLock) {
val localLog = localLogWithEpochOrThrow(
fetchPartitionData.currentLeaderEpoch,
fetchParams.fetchOnlyLeader
)
readFromLocalLog(localLog)
}
}
}
private def readRecords(
localLog: UnifiedLog,
): LogReadInfo = {
// 调用 localLog.read 方法读取数据
val fetchedData = localLog.read(
fetchOffset,
maxBytes,
fetchIsolation,
minOneMessage
)
// 返回数据
new LogReadInfo(
fetchedData,
Optional.empty(),
initialHighWatermark,
initialLogStartOffset,
initialLogEndOffset,
initialLastStableOffset
)
}def read(
startOffset: Long,
maxLength: Int,
minOneMessage: Boolean,
maxOffsetMetadata: LogOffsetMetadata,
includeAbortedTxns: Boolean
): FetchDataInfo = {
// 获取 最大Offset >= startOffset 的 Segment
var segmentOpt = segments.floorSegment(startOffset)
// Do the read on the segment with a base offset less than the target offset
// but if that segment doesn't contain any messages with an offset greater than that
// continue to read from successive segments until we get some messages or we reach the end of the log
var fetchDataInfo: FetchDataInfo = null
while (fetchDataInfo == null && segmentOpt.isDefined) {
val segment = segmentOpt.get
val baseOffset = segment.baseOffset
val maxPosition =
// Use the max offset position if it is on this segment; otherwise, the segment size is the limit.
if (maxOffsetMetadata.segmentBaseOffset == segment.baseOffset) maxOffsetMetadata.relativePositionInSegment
else segment.size
// 调用 segment.read 方法读取数据
fetchDataInfo = segment.read(startOffset, maxLength, maxPosition, minOneMessage)
if (fetchDataInfo != null) {
if (includeAbortedTxns)
fetchDataInfo = addAbortedTransactions(startOffset, segment, fetchDataInfo)
} else segmentOpt = segments.higherSegment(baseOffset)
}
}/**
* Read a message set from this segment beginning with the first offset >= startOffset. The message set will include
* no more than maxSize bytes and will end before maxOffset if a maxOffset is specified.
*/
def read(
startOffset: Long,
maxSize: Int,
maxPosition: Long = size,
minOneMessage: Boolean = false
): FetchDataInfo = {
// log.slice 切分 日志数据
new FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize),
adjustedMaxSize < startOffsetAndSize.size, Optional.empty())
}